Can memory systems track who a user is, what they do, and what they prefer — and keep it current — across months of multi-app activity?
1University of Minnesota 2University of North Carolina at Charlotte 3Johns Hopkins University 4Cisco 5Adobe
Preprint · ✉ Corresponding author: zrliu@umn.edu
LLM agents increasingly act as personal assistants that must remember a user's profile over months — who they are (attributes), what they routinely do (habits), and what they prefer (preferences) — and keep it updated as jobs, routines, and tastes drift. Existing benchmarks evaluate this "memory" through short, simplified interactions, missing three core properties of real long-horizon behavior: a user's profile is heterogeneous (attributes, habits, and preferences evolve on different timelines); its changes are causally driven by external context such as life events; and its evidence is scattered across many small actions in different apps rather than stated explicitly.
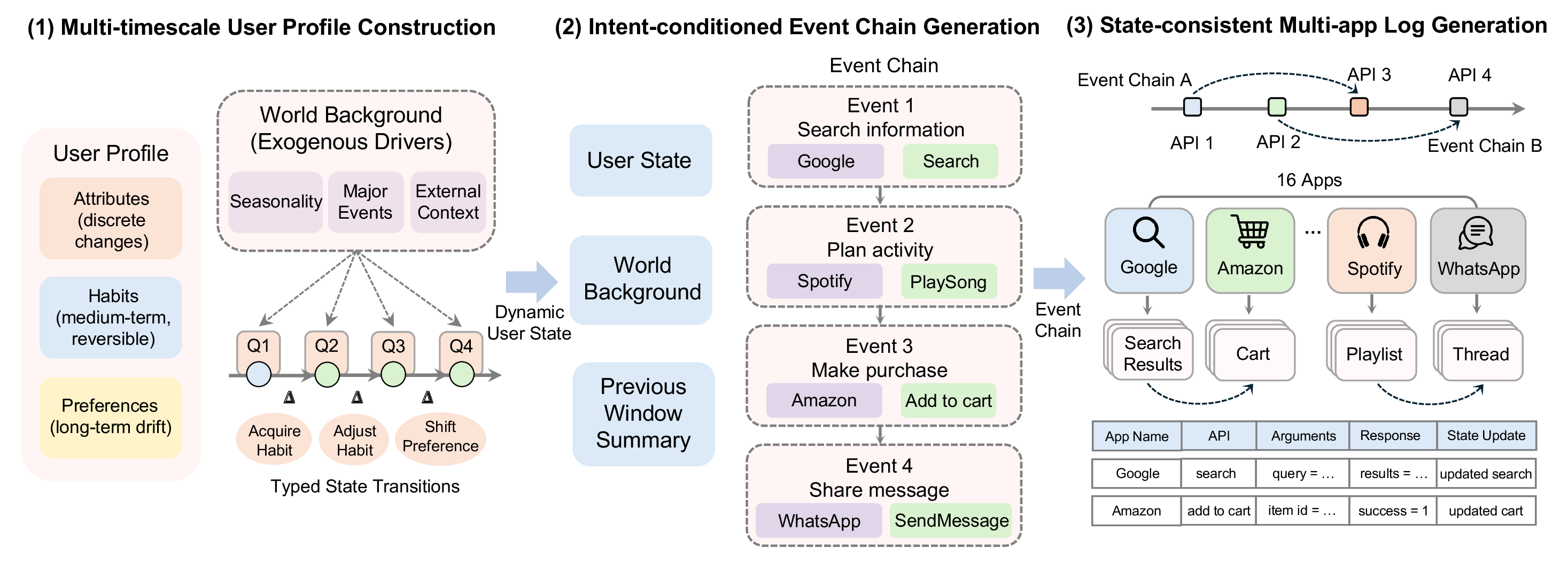
We introduce DynamicMem, a synthetic benchmark that constructs 15 months of activity for each user — the kind of long-term, multi-app data that real users' privacy keeps out of reach. It provides user-consistent trajectories averaging 2.2M tokens and 1,772 grounded events per user across 16 applications, with profiles that evolve under seasons and life events, and every recorded action reflecting the user's profile at that moment. We evaluate at five quarterly checkpoints to track how systems scale as history grows. Benchmarking five representative memory systems exposes problems a single accuracy score hides — detailed below.
A quick tour of the setting before the results.
Each user has a 15-month trajectory of activity across 16 apps. We place five quarterly checkpoints (C1–C5); at each one a memory system sees only the app logs up to that date and must answer about the user's state at that moment. Accessible history therefore grows from ~3 months at C1 to ~15 months at C5 — so later checkpoints reveal how a system scales as evidence piles up, and whether it updates facts that have changed.
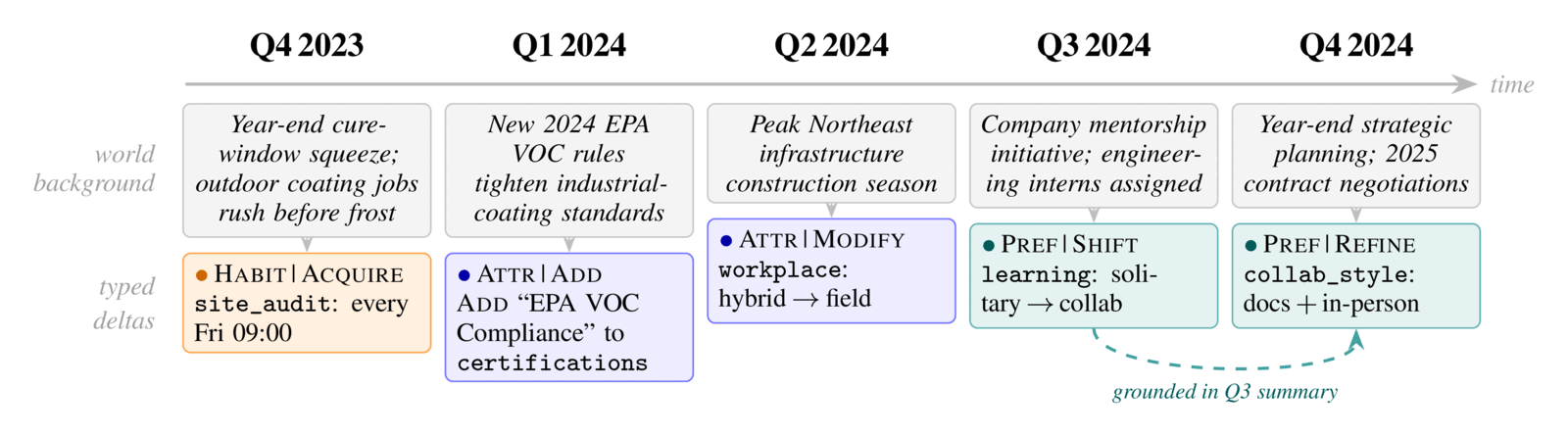
Facts and possessions — what the user has or is. Change discretely on life events.
e.g. primary vehicle: a 2022 BMW 530e; home city: Pittsburgh.
Recurring routines — what the user regularly does. Adapt to context and may revert.
e.g. a Saturday-morning grocery run; a weekday 6 km jog.
Comparative inclinations — what the user tends to choose. Drift gradually, rarely stated outright.
e.g. a leaning toward healthier food; quiet, self-paced learning.
Nothing in the profile is stated outright. A single user intent unfolds as a causally linked event chain across several apps over months, so the evidence for any one fact is fragmented — a memory system has to piece it back together.

Fill the blank fields of the user's current profile in a fixed schema, condensing many time-scattered logs.
Handle a request whose scenario gives only time and place — the user-state needed is deliberately withheld.
e.g. "Sunday 10:15" → draft a reminder for the user's weekend grocery run at its usual time and place.

Both tasks are scored field by field by an LLM judge on a Core axis (is the central fact right?)
and a Detail axis (are the specifics preserved?), combined as
s = 0.8·Core + 0.2·(Detail/2).
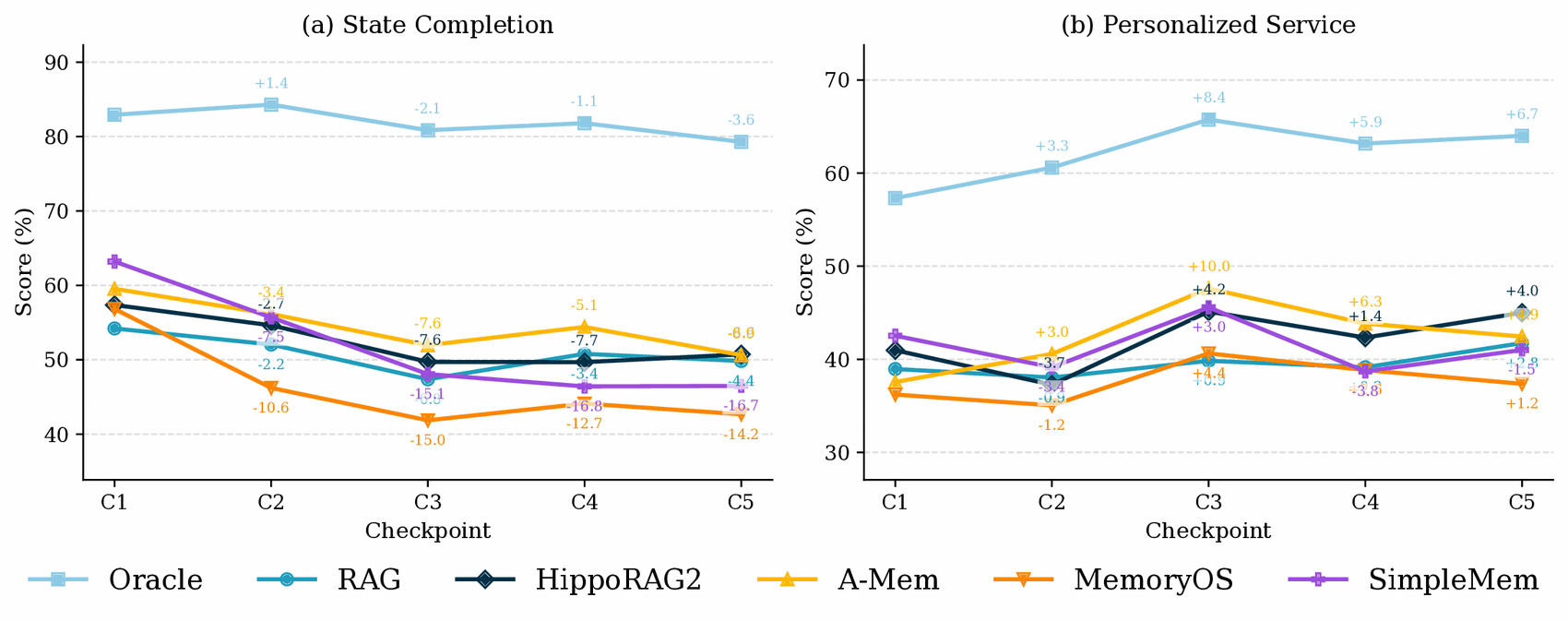
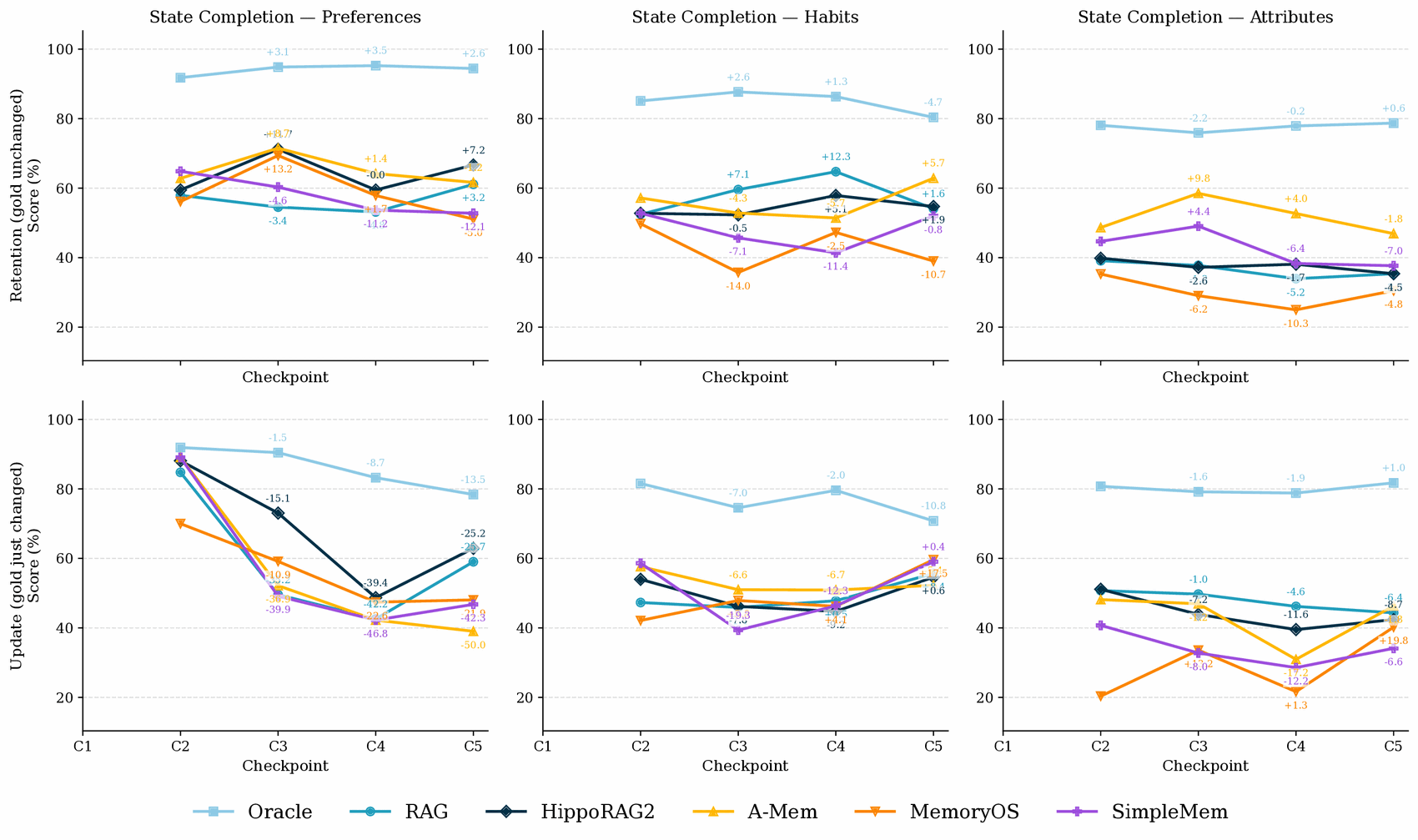
Benchmarking Oracle plus five memory systems — RAG, HippoRAG2, A-Mem, MemoryOS, and SimpleMem — at the five quarterly checkpoints C1–C5.
From C1 to C5, State Completion declines for every system (−4.4 RAG, −6.6 HippoRAG2, −8.9 A-Mem, −14.2 MemoryOS, −16.7 SimpleMem). Yet Personalized Service shows no such decay — it is higher at C5 than C1 for four of the five systems. Since both tasks read the same memory, the bottleneck is recovering state, not acting on it.
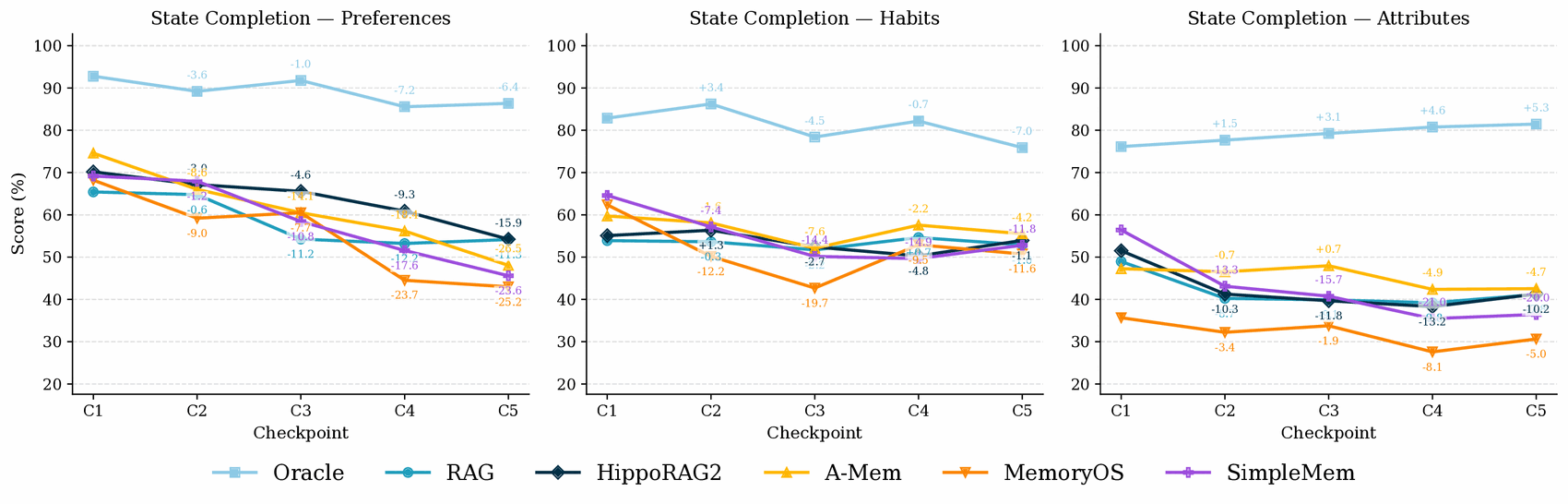
Breaking State Completion down by state family, preferences account for most of the decline (e.g. −26.5 for A-Mem from C1 to C5) and degrade steadily — they are implicit, inferred from many scattered logs that later evidence blurs. Habits stay roughly flat (recurring behavior adds redundant evidence), and attributes drop early then hold.
A falling score can mean forgetting a long-standing fact (retention) or failing to adopt a changed one (update) — distinct failures an aggregate curve hides. The same mechanism that lets a system hold a stable fact often blocks it from adopting a changed one, and the trade-off differs by family: append-only stores (RAG, HippoRAG2) adopt changes fast but forget; consolidating stores (A-Mem, SimpleMem, MemoryOS) retain but blur old and new.
Every failure is labelled by what the memory system delivered to the answer model — isolating memory failures from answer-model behaviour.
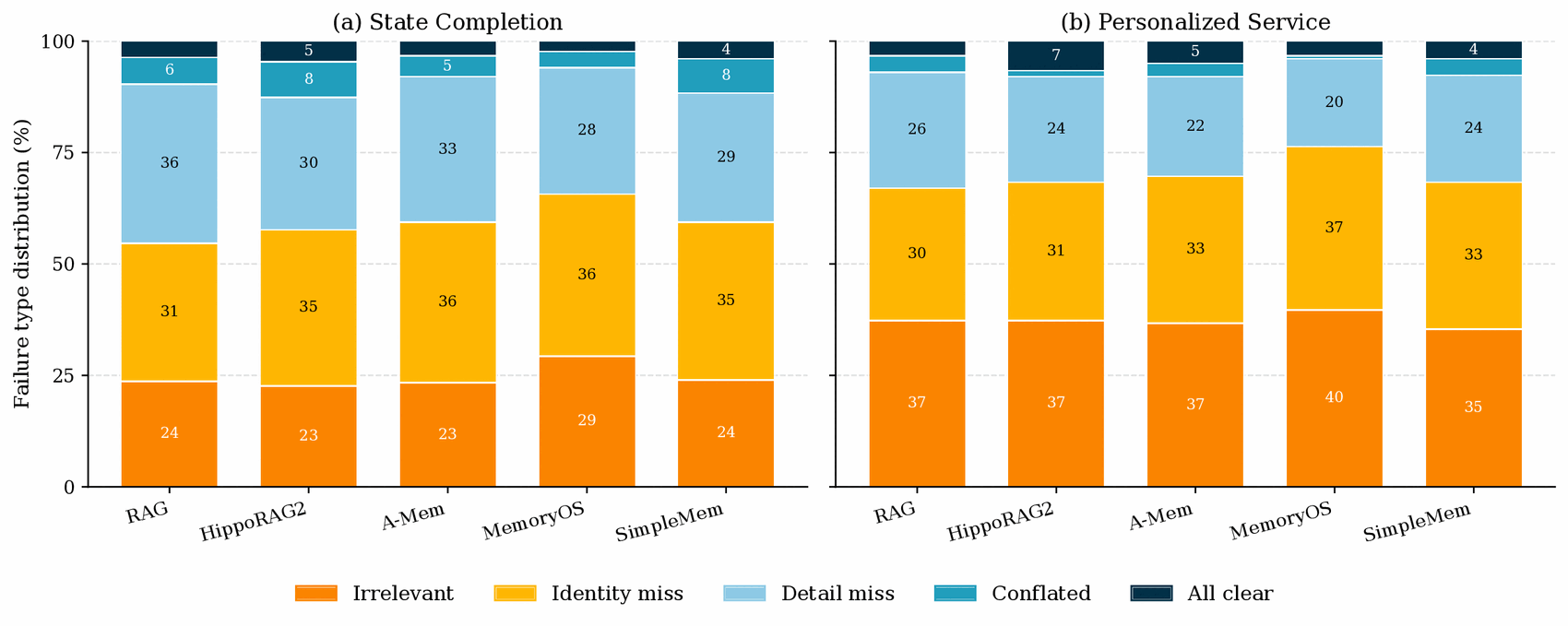
The four systems that build structure beyond raw chunks (A-Mem, HippoRAG2, MemoryOS, SimpleMem) all concentrate at 35–36% Identity Miss with Detail Miss falling to 28–33%; RAG shows the opposite balance (36% Detail Miss). Merging and summarizing preserve surrounding detail but abstract away the named anchor — and the identity-miss rate sits within a point of 35% across four very different mechanisms, suggesting it is a systemic challenge of structured memory.
MemoryOS shows the highest Irrelevant Evidence rate on both tasks (29% SC vs 23–24%; 40% PS vs 35–37%); combined with its Identity Miss, roughly two-thirds of its failures involve evidence that never pins down the user's state. Compacting many logs into a multi-level summary surfaces an abstracted view rather than the specific log a precise state query needs.
All Clear — evidence complete and unambiguous, yet the prediction still wrong — stays at just 2–7% across all ten (system, task) combinations. In other words, more than 93% of failures are bounded by what the memory system could deliver, not by what the answer model did with it. The headroom lies in memory itself.
@article{xie2026dynamicmem,
title = {DynamicMem: A Long-Horizon Memory Benchmark in Real-World Settings},
author = {Xie, Wenya and Zhou, Shengming and Li, Zelin and Parsa, Pouya and
Zhou, Shuang and Ding, Xinheng and Arvind, Chinmay and Wang, Guanchu and
Braverman, Vladimir and Payani, Ali and Zheng, Yantao and Liu, Zirui},
journal = {arXiv preprint arXiv:XXXX.XXXXX},
year = {2026}
}